
Priceless
[CVPR'23 WAD] Keynote - Ashok Elluswamy, Tesla 리뷰 본문
[CVPR'23 WAD] Keynote - Ashok Elluswamy, Tesla 리뷰
Hyun__ 2023. 9. 23. 14:23아래 영상을 리뷰합니다 (변역 및 정보 추가)
https://www.youtube.com/watch?v=6x-Xb_uT7ts&ab_channel=WADatCVPR
영어 해석, 용어 등 오류가 있을 수 있습니다. 피드백 남겨주시면 감사하겠습니다 :)
Introduction
Full Self Driving(FSD, Beta)

미국과 캐나다에서 40 만 대의 테슬라에서 FSD 동작, FSD를 통한 누적 2억 5천만 마일을 달성했습니다.
Radar, LiDAR, Ultrasonics, HD Maps 없이 8개의 360도 카메라만을 전적으로 사용하여 주행합니다.
Modern Neural Net Based Tech Stack을 통해 FSD를 구현했습니다.
Occupancy Networks (점유 네트워크)

Ontology(존재물)가 voxel(Volume Pixel, 체적 픽셀)로 점유되어 있는지(occupied) 감지하는 것을 Occupancy network라고 합니다.
실제 3D 공간에서 어떤 voxel로 점유되어 있는 확률을 실시간으로 예측하는 것입니다.
NeRF(Neural radiance Fields, 2D 이미지로 3D 재구성)와 유사하지만, 8대의 카메라로 스트리밍된 비디오를 통해 차 주변의 모든 공간에서 voxel의 occupancy를 예측합니다.
Occupancy Network ARXIV: https://arxiv.org/abs/1812.03828
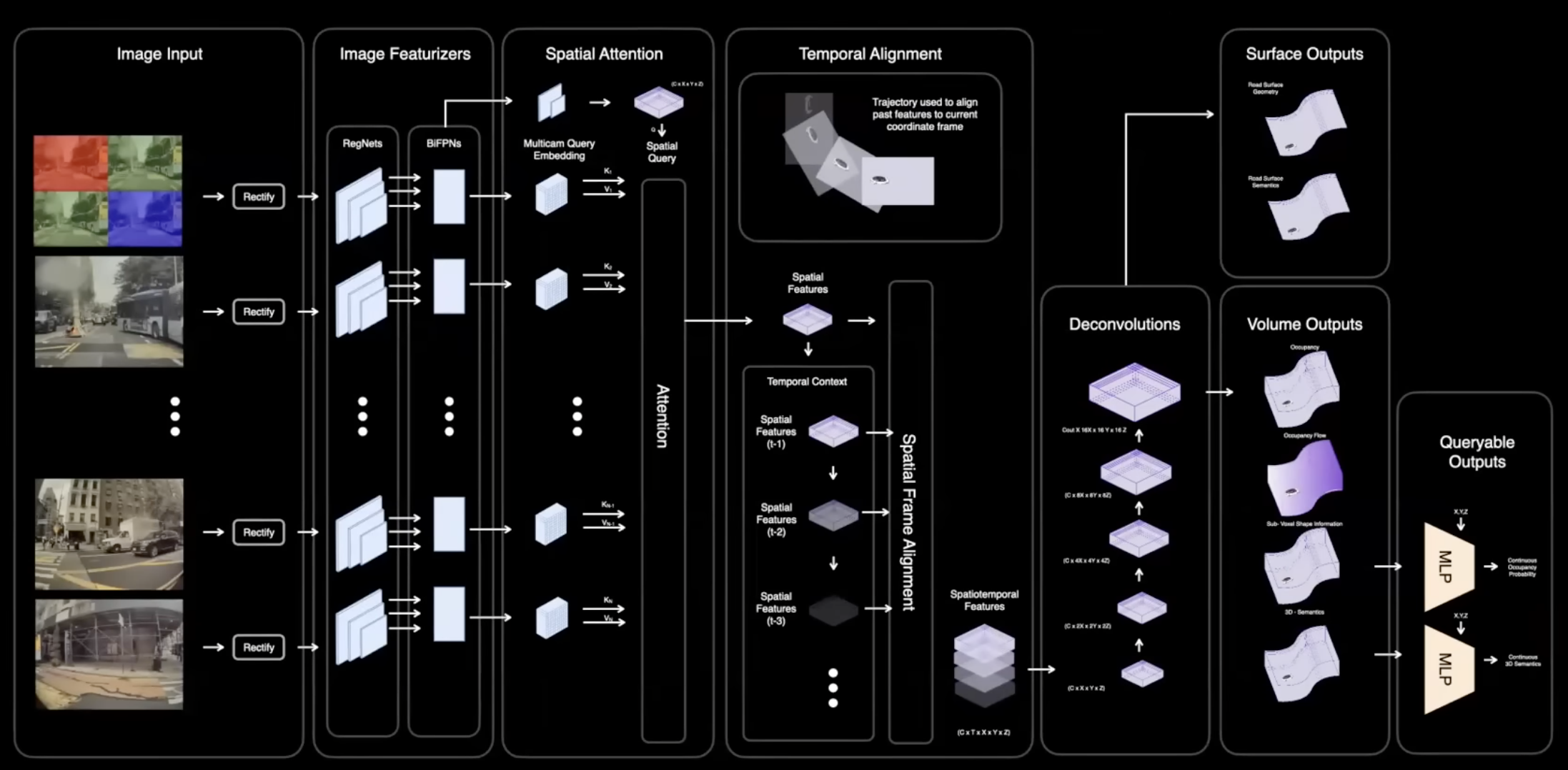
Occupancy Network의 아키텍쳐는 다음과 같습니다. backbone 네트워크로 RegNet 사용하지만 원하는 다른 네트워크를 선택할 수 있습니다. Transformer block에 모여 feature를 형성하고 실제 예측에 업샘플링합니다.
Generative Modeling of Lanes
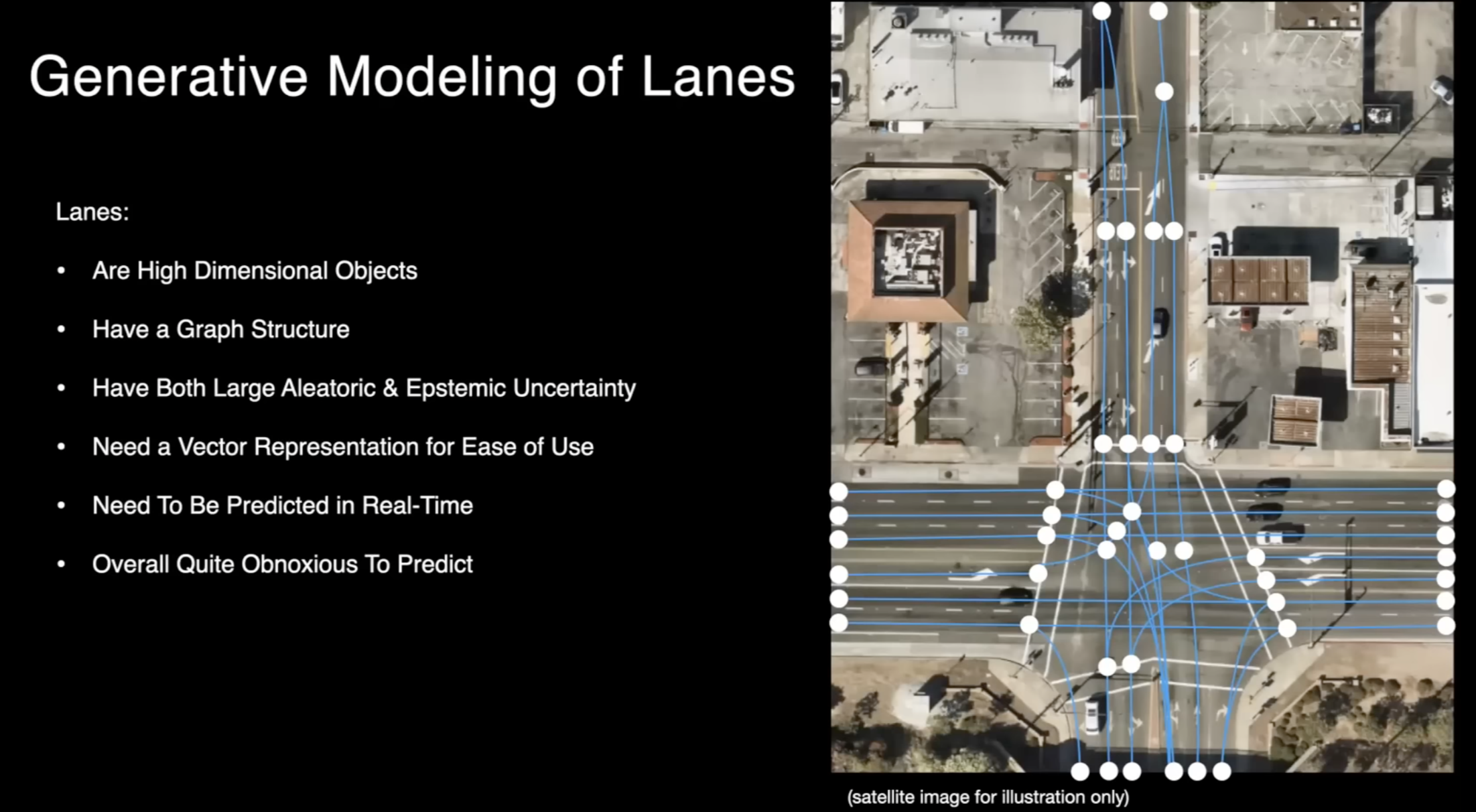
동일한 아키텍처 내에서 모델링은 차선 및 도로와 같은 운전 작업에 필요한 다른 작업에도 사용할 수 있습니다.차선과 도로는 운전 작업에 매우 중요하지만, 차선은 예측하기는 꽤 까다로운 작업 중 하나입니다. 차선은 차원이 높은 객체로, 1차원이나 2차원이 아니라 고차원으로 그래프 구조와 같은 구조를 가지고 있습니다.
차량은 자기 자신만의 구조를 가지고 있으며 로컬하게 존재합니다. 하지만 차선은 전체 도로를 걸쳐 뻗을 수 있으며 시야 내에서 여러 마일에 걸쳐 볼 수 있으며 분기점이 생기고 병합되어(fork and merge) 모델링에 어려움을 줄 수 있습니다.
차선은 때로는 큰 불확실성을 가집니다. 가령, 차선이 가려져 보이지 않을 수 있거나, 밤에만 일부 차선이 보이며, 심지어 모든 것이 보일 때에도 사람들은 본인이 보는 것이 두 차선인지 아니면 한 차선인지에 대해 확신하지 못할 수 있습니다.
그것을 어떤 종류의 예측으로만 하면 다운스트림에서 사용하기가 매우 어려우므로, 그것을 일종의 벡터 표현으로 예측하는 것이 더 좋습니다. 이러한 표현은 사용 편의성을 돕기 위해 다각형 선, 곡선 등으로 사용됩니다. 그리고 이 모든 것은 실시간으로 이루어져야 합니다.
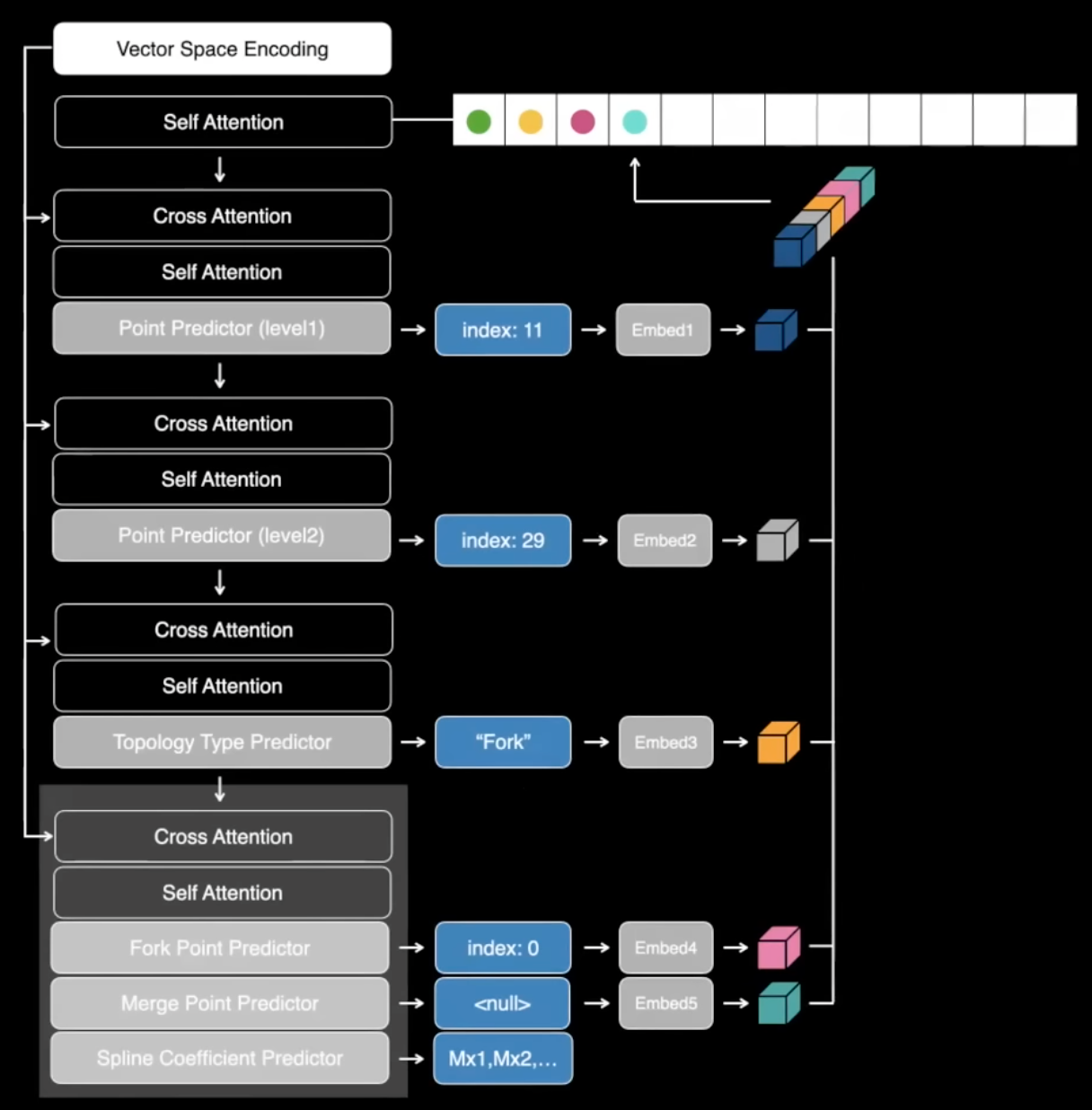
차선을 모델링하는 방법에 관해서 말하면, GPT와 유사한 면이 있다고 할 수 있습니다. 따라서 차선을 토큰화하고 토큰을 하나씩 예측할 수 있습니다. 언어와는 달리 대부분 선형적인 것이 아니라 우리는 전체 그래프 구조를 예측해야 합니다. 따라서 예측한 후에는 후처리가 필요하지 않게끔 End-to-End 로 모든 작업이 수행됩니다.
Object Prediction & Properties
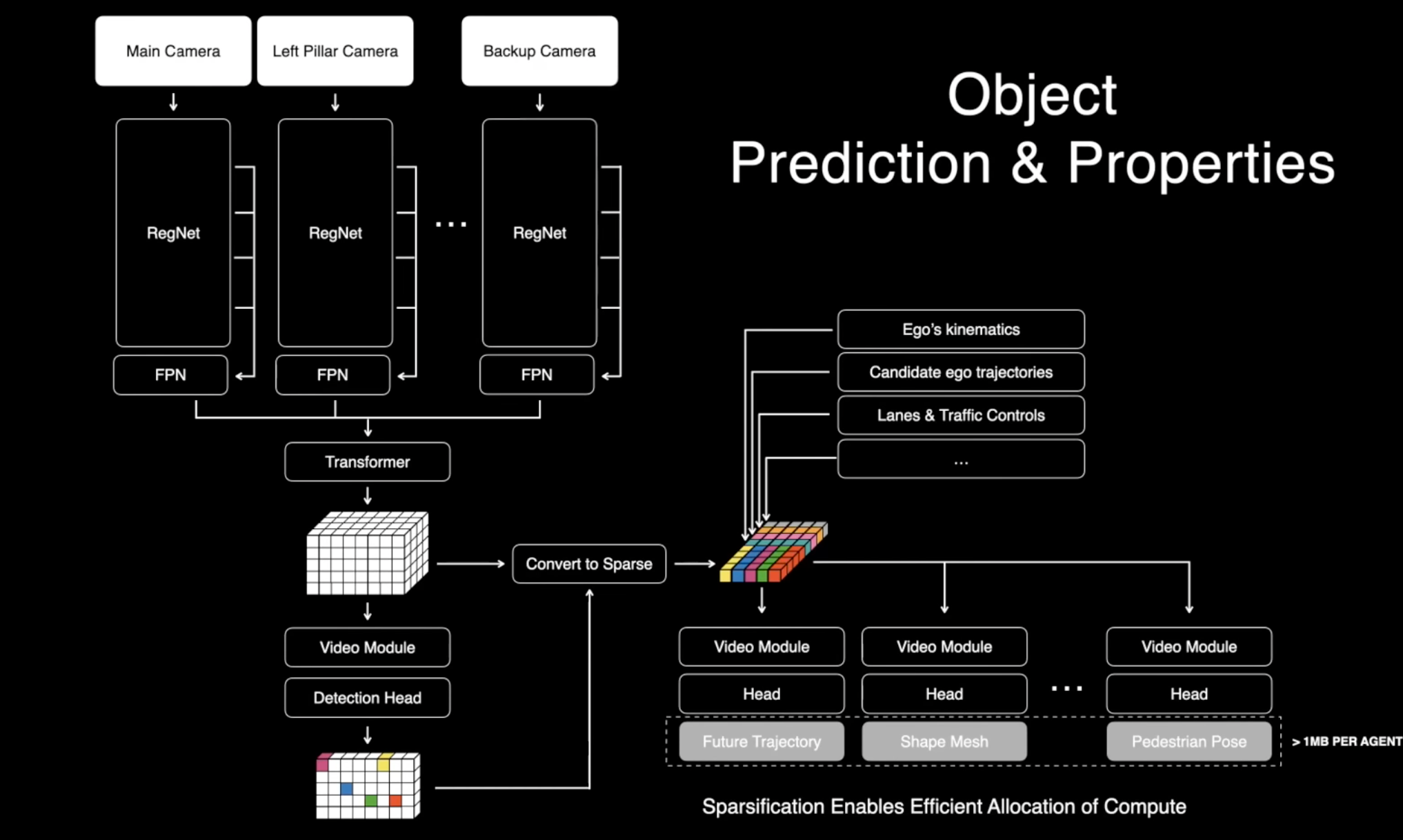
자율 주행의 또 다른 중요한 작업은 분명히 이동하는 물체입니다. 차량, 트럭, 보행자 등과 같은 것들이 있죠. 그리고 이러한 물체를 감지하는 것만으로 충분하지 않습니다. 이들의 완전한 운동 상태(kinematic 상태)와 모양 정보, 미래 예측 등이 필요합니다. 이전에 설명한 모델들, 차선 모델과 물체 모델 모두 어떤 면에서는 Multimodal 모델입니다. 이 모델들은 카메라 비디오 스트림뿐만 아니라 이동체 자신의 운동(kinematic) 정보와 같은 다른 입력도 받아들입니다. 우리는 navigation instructions도 렌즈에 제공하여 어떤 차선을 사용할지 등을 안내합니다. 모든 것이 네트워크 내에서 처리되므로 이것은 일종의 현대적인 머신 러닝 스택으로 볼 수 있습니다. 후처리 작업 대신 모든 것을 결합하고 인식을 End-to-End 로 처리하는 것입니다.

여기에서 이러한 모델들의 예측을 볼 수 있습니다. 여기서 보이는 차선과 차량들은 모두 이러한 네트워크에 의해 예측되었으며 많은 후처리가 있습니다. 여기서 보이는 것들에는 추적 또는 그와 유사한 것들이 없습니다. 전반적으로 말하자면, 이것은 꽤 안정적인 것으로 보입니다. 여기 차량들에서 나오는 녹색 선들은 그들의 미래를 예측하는 것으로, 이것은 현재로서는 표준 작업의 한 부분인 것 같습니다.
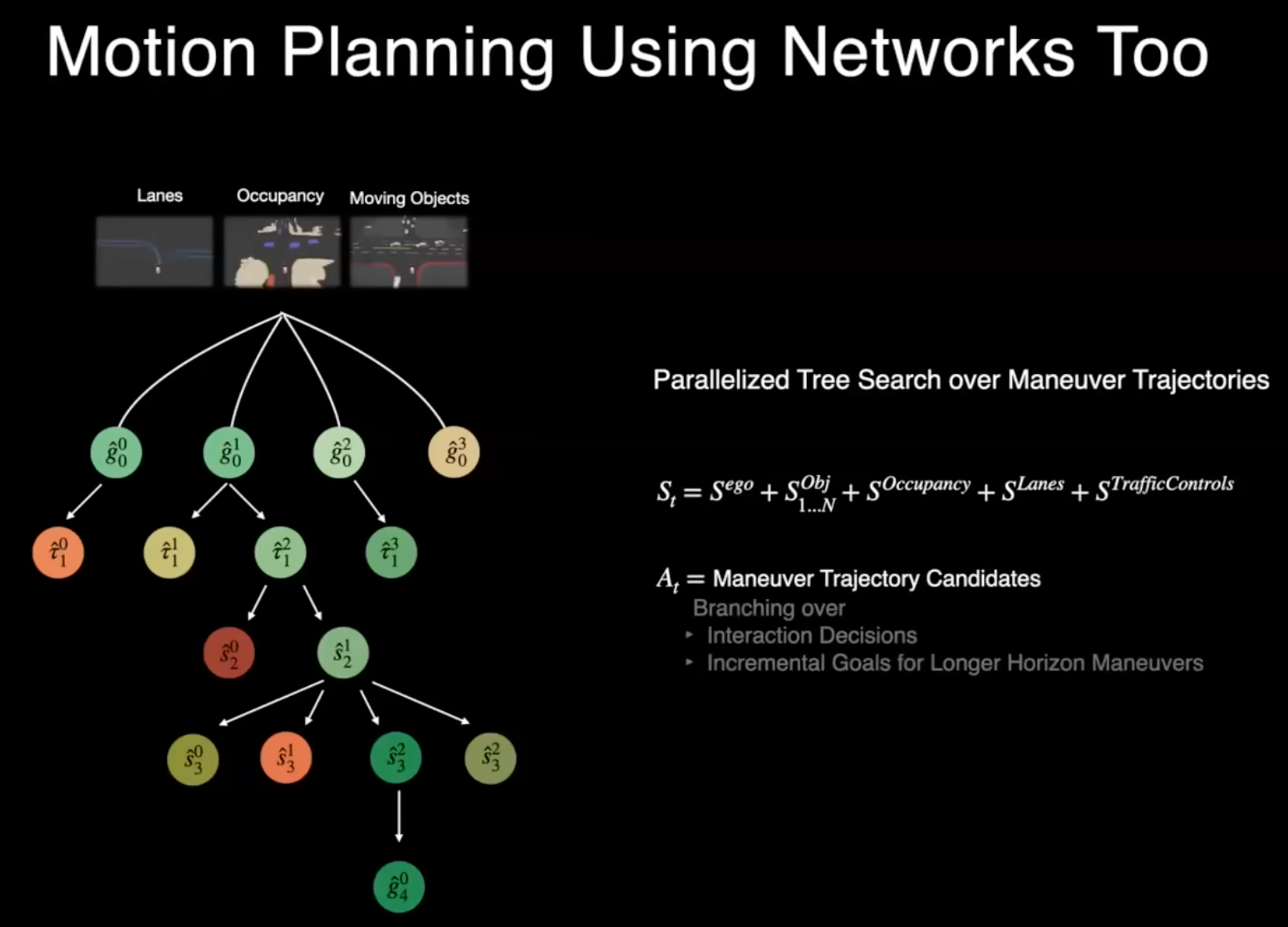
차선, 점유, 물체와 같은 모든 이러한 지각 정보를 가지고 나면 교통 규제와 같은 몇 가지 추가 정보도 포함하여 전체 움직임 계획을 네트워크만 사용하여 수행할 수 있습니다. 본질적으로 별도의 것이 아닌 하나의 작업으로 생각할 수 있습니다.
Fleet Auto-Labeling (차량 함대)
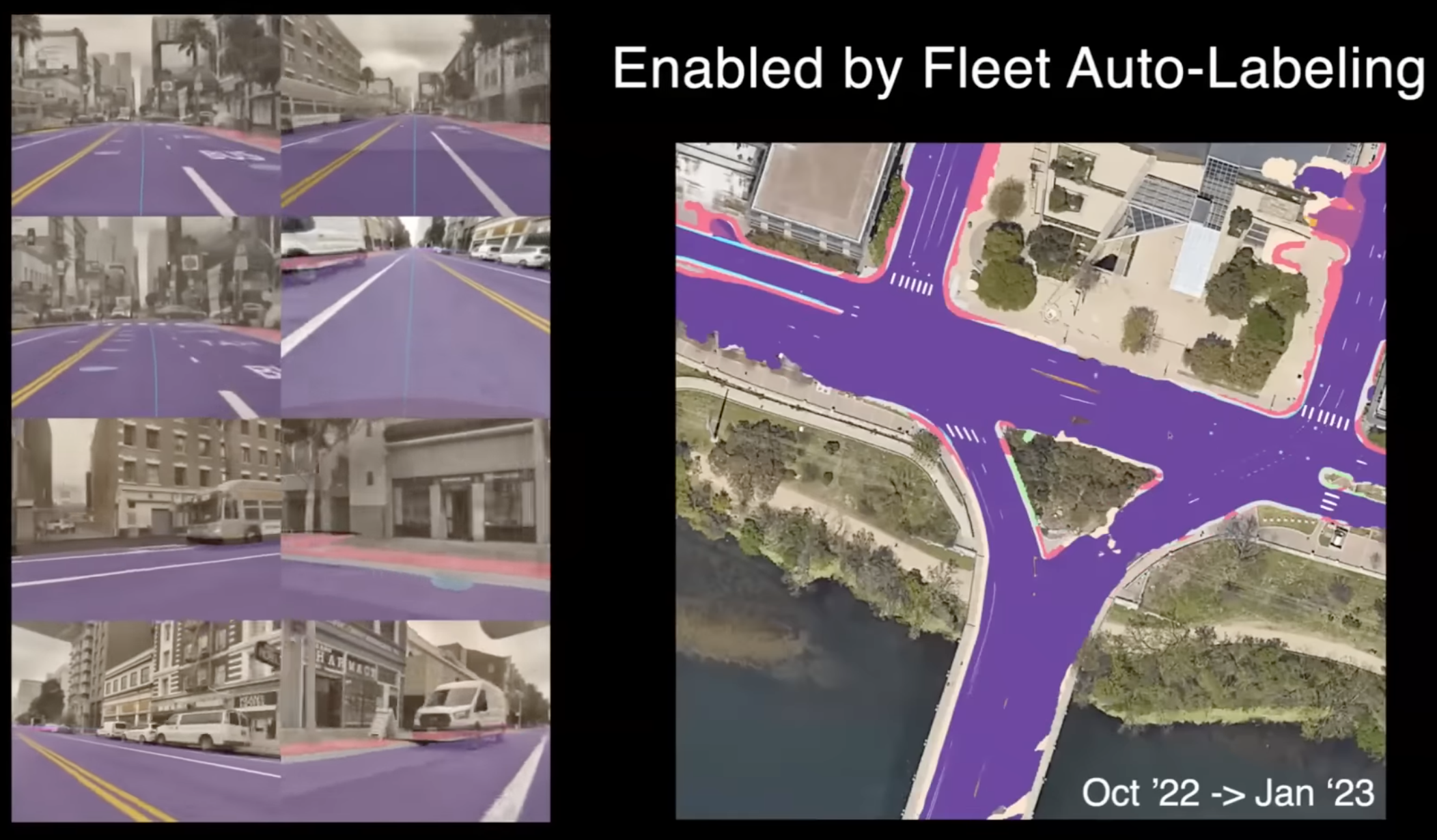
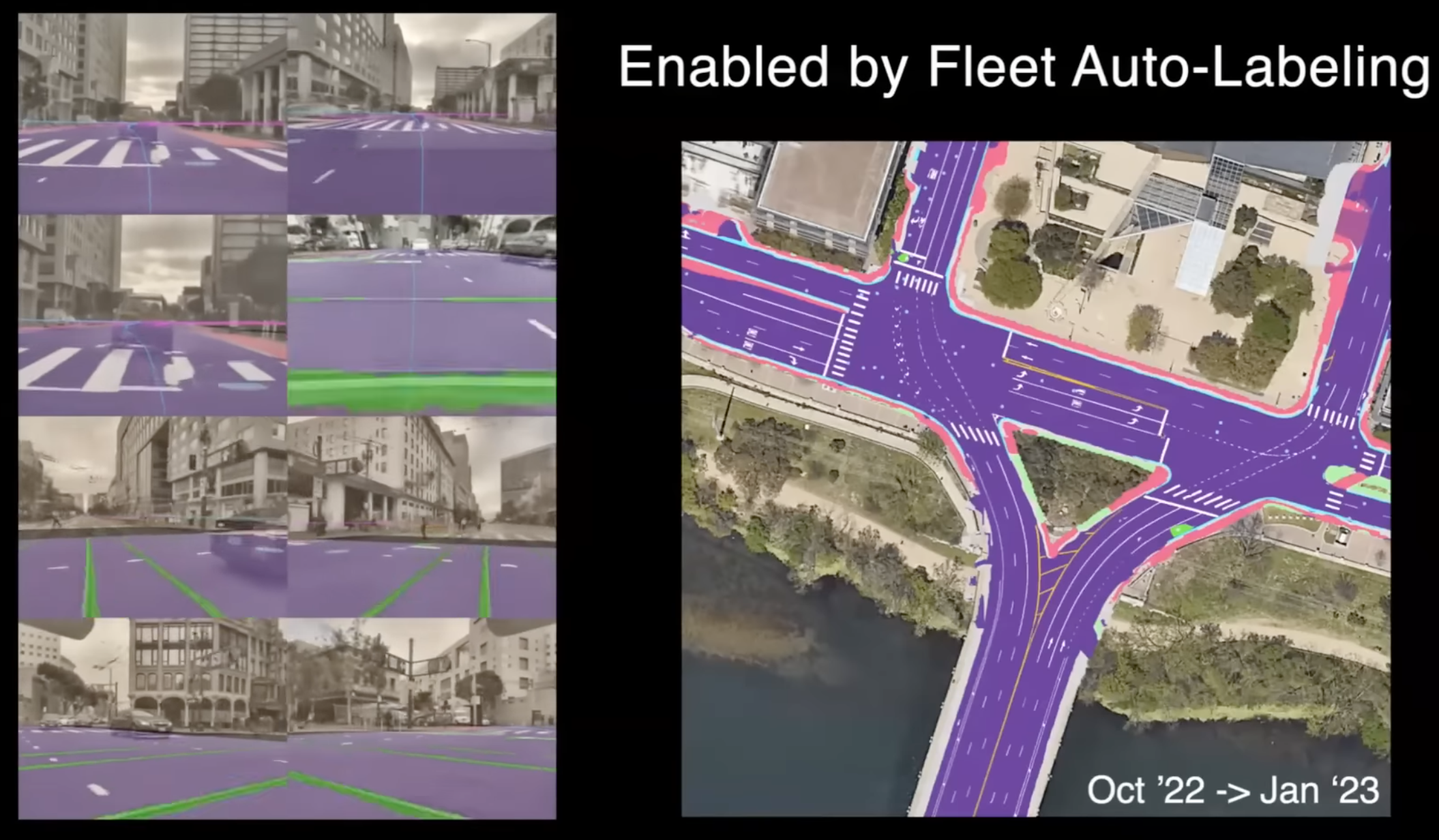
그렇다면 이 모든 것이 어떻게 가능한 것일까요? 이것은 전체 차량 fleet로부터 데이터를 제공하는 정교한 자동 labeling 파이프라인을 구축했기 때문이라고 생각합니다. 전 세계의 수백만 개의 비디오 클립에서 데이터를 가져올 수 있습니다.
왼쪽에 보이는 것은 multi-trip reconstruction의 예시입니다. 여기서 테슬라 차량이 지나가는 위치를 선택하고, 해당 위치에서 여러 차량의 비디오 클립과 운동(Kinematic) 데이터 등을 수집합니다. 그런 다음 이 모든 것을 통합하여 전체 3D 장면을 구성합니다. 여기서 보이는 40개의 선은 서로 다른 차량이 전 세계에서 다른 trip을 하는 것으로, 매우 잘 정렬되어 있습니다.
핑크색 선과 청록색 선은 다른 차량의 다른 trip을 나타냅니다. 이 multi-trip reconstruction은 전 세계 어디에서든 차선, 도로, 모든 것을 직접 fleet에서 얻을 수 있도록 해주었습니다.

이러한 모든 카메라로부터의 궤적 보정과 기본 구조를 갖게 되면 전체 장면을 재구성하는 데 유용한 작업을 할 수 있습니다. 지면 표면을 볼 수 있는데, 이것은 아주 잘 재구성되어 있으며, 이중 시야나 흐림과 같은 artifact가 없습니다. 모든 것이 올바르게 보이며, 이것은 NeRF와 일반적인 이론을 재구성한 혼합된 접근 방식입니다.
NeRF의 시각적 결과는 멋질 수 있지만 매우 흐릿하고 탁한 경우가 있습니다. 하지만 위 영상에서는 매우 잘 작동하는 혼합 접근 방식을 가지고 있으며 여기서는 장애물, 차량, 트럭 등이 꽤 정확하게 재구성되었습니다.
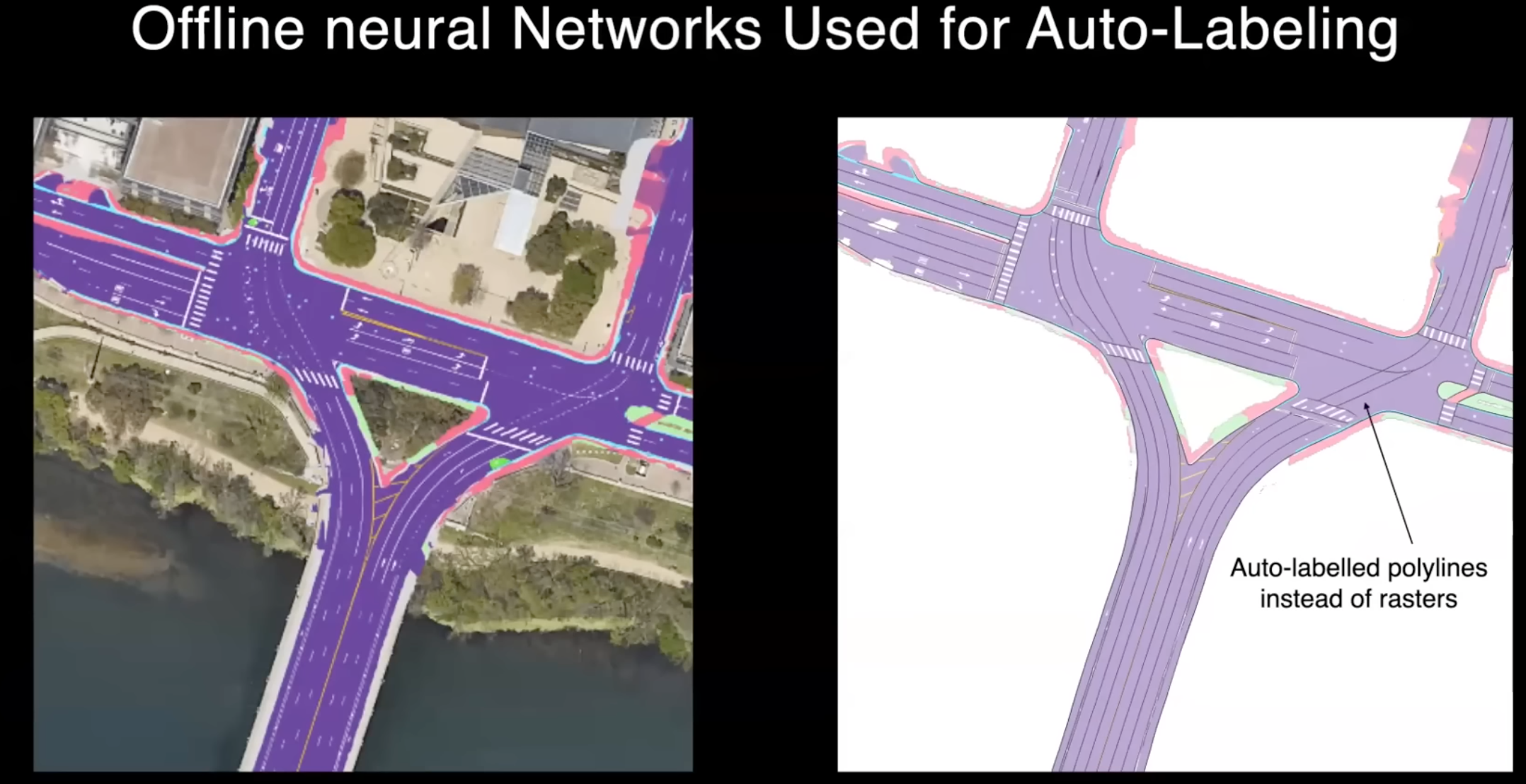
이러한 재구성이 완료되면, 우리는 원하는 label을 생성하기 위해 오프라인에서 더 많은 Neural Network를 실행합니다. 이전에 말한 것처럼 차선에 대해서는 매우 쉽게 사용하기 위한 일종의 벡터 표현이 필요합니다. 따라서 raster 직접 사용 대신에 raster 위에서 실행되는 신경망을 사용하고, 그런 다음 벡터 표현을 생성하여 온라인 스택에 label로 사용할 수 있도록 합니다.

차선과 유사하게 차선과 도로를 재구성한 후 교통 신호등을 자동으로 labeling할 수 있습니다. 여기에서는 인간의 입력 없이 시스템에서 자동으로 labeling한 교통 신호등을 보고 있습니다. 이들은 다중 뷰에서 일관성 있게 생성됩니다. 신호등의 모양, 색상, 관련성을 예측할 수 있으며, 옆에 있는 밝은 교통 신호등도 카메라 뷰로 정확하게 재투영됩니다. 이는 모든 것을 함께 보정하는 자동 교정 시스템 덕분에 가능하며, 3D 공간에서 Pixel Perfect하게 작동합니다.

이 모든 예측은 카메라로부터 세계를 이해하는 슈퍼스코프(Supersport)를 제공합니다. 이미 이것을 여러 다양한 장소에서 사용할 수 있는 기반 모델이라고 생각하려고 노력하고 있으며, 이러한 예측은 FSD(Full Self-Driving)를 어떤 곳에서든 작동할 수 있게 돕습니다. 지리적으로 제한할 필요가 없으며, 새롭게 만들어진 도로에서 작동해도 잘 작동합니다. 왜냐하면 인간은 완벽한 운전자가 아니기 때문에 때때로 도움이 필요하기 때문입니다.
왼쪽 사진에 있는 운전자가 정지 신호를 무시하고 거의 붉은색 차량에 충돌직전까지 달려갔는데, 우리 시스템은 자동으로 브레이크를 걸었습니다. 오른쪽에서 운전하다가 누군가가 나타나서 차로 앞에 끼어들었는데, 이것은 꽤 위험한 상황이지만 시스템이 이를 빠르게 감지하고 브레이크를 걸었습니다.
이것이 1980년대부터 있는 AEB 시스템과 다른 점은 무엇일까요? 교차로 개체는 자신의 차선에 있는 차량과 달리 정지할 시간이 있는지 여부를 알아야 하며, 정지선은 무엇인지, 교통 신호등이 있는지, 그리고 만약 교차한다면 어떤 차선으로 돌아갈 것인지 등을 알아야 합니다. 교차로 개체가 어디로 가야 할지와 어디로 가기가 가능한지를 이해하기 위해 수행해야 할 작업이 많이 있으며, 그저 차량을 감지하고 속도 등을 파악하는 것만큼 간단하지 않습니다.
Learning a General World Model
Is a foundation model just a bunch of tasks concatenated together?
하지만 이것은 실제로 단순한 기반 모델이며, 이러한 여러 작업을 연결하는 것뿐인가? 아니면 더 많은 것이 가능할까요?

우리는 가능할 것이라고 생각합니다. 예를 들어, 점유에 대해서 얘기하면, 비록 그것이 꽤 일반적인 작업이긴 하지만, 그 공간에서 표현하기 어려운 것들도 있습니다. 곧 더 자세한 내용을 다룰 것이지만, 그것이 우리가 임의의 것을 표현할 수 있는 더 일반적인 월드 모델을 학습하고 있는 이유입니다. 이 경우에 우리가 하는 것은, 과거 또는 다른 것에 조건을 걸어 미래를 예측할 수 있는 신경망을 가지고 있습니다. 물론 누구나 영원히 이것을 연구하고 싶어했고, 최근의 Horizon 생성 모델들(예: Transformers, 확산 등)로 우리는 이를 실현할 수 있게 된 것 같습니다.
여기서 보는 것은 단순히 과거 비디오를 바탕으로 생성된 비디오 시퀀스입니다. 네트워크는 미래에서 일부 샘플을 예측합니다. 아마도 가장 가능성이 높은 샘플을 예측하고 있을 것입니다. 그리고 여기서 주목할 점은 한 카메라에만 예측되는 것이 아니라 차 주변의 모든 여덟 대의 카메라에 대해 함께 예측하고 있으며, 차의 색상이 카메라 간에 일관되게 유지되고 있으며, 물체의 움직임도 3D에서 일관되게 나타나고 있습니다. 이러한 모든 것은 우리가 명시적으로 3D에서 어떠한 것도 요청하거나 어떤 3D 사전 정보도 제공하지 않은 상태에서, 네트워크가 스스로 깊이와 움직임을 이해하고 있는 것입니다. 그리고 모든 것은 미래의 RGB 값만을 예측하기 때문에 ontology는 매우 일반적입니다.

또한 행동에 따라 조건이 설정될 수 있으며 몇 가지 예를 들어보겠습니다. 여기 왼쪽에서 차량이 차선을 따라 운전하고 있으며 "이 차선을 유지하고 계속 운전해"하고 있습니다. 그리고 앞서 언급했듯이 모델은 모든 geometry flow를 예측하며 3차원을 이해합니다. 오른쪽에서는 차선을 오른쪽으로 변경하도록 요청합니다. 다시 재생해 보겠습니다. 왼쪽에서는 그냥 직진하고, 우리가 직진하라고 요청하면 모델도 직진하고, 오른쪽에서는 차선 변경을 요청하면 차선을 변경합니다. 이 두 출력에 대한 과거 문맥은 동일합니다. 따라서 동일한 과거를 기반으로 다른 미래를 요청하면 모델은 다른 미래를 생성하거나 상상할 수 있습니다. 이것은 매우 강력한 기능이며, 이제 다양한 행동을 기반으로 다른 미래를 시뮬레이션할 수 있는 Neural Network 시뮬레이터가 있기 때문에 매우 강력합니다. 기존의 게임 시뮬레이터와 달리 이것은 명시적인 시스템에서 설명하기 어려운 것들을 표현할 수 있으므로 훨씬 강력합니다. 몇 가지 추가 예시를 보여줄 것이지만 이것은 매우 강력하며, 또한 차량과 같은 다른 물체의 움직임, 의도 및 자연적인 행동을 명시적으로 표현하기가 매우 어렵지만 이 세계에서는 이를 매우 쉽게 표현할 수 있습니다.

이것은 단순히 RGB로 끝나지 않습니다. 당연히 RGB뿐만 아니라 semantic segmentation 또는 3D 공간에서도 이러한 미래 예측 작업을 수행할 수 있습니다. 과거와 당신의 행동 유도 또는 유도하지 않고도 단순히 과거에 기초하여 다양한 미래를 예측할 수 있습니다.

여기 몇 가지 예시가 있지만, 이러한 것을 표현하기 위해서는 장면에서 일어나는 것을 나타내기 위한 것이 필요할 것으로 생각합니다. 사진에서 보듯이 연기가 많이 나오고 종이가 공중에 날아 다니는 등, 이러한 상황은 차량의 위치가 어디인지를 나타내는 것만으로는 충분하지 않을 것입니다. 종이가 어떤 물질로 이루어져 있는지, 연기가 있는지, 이러한 세부 사항을 어떻게 알 수 있을까요?
연기는 차를 통과할 수 있지만, 공간을 차지하고 빛은 통과하지 않는다는 점을 고려해야 합니다. 운전에는 많은 미묘한 점들이 있으며, 전 세계 어디에서나 운전할 수 있는 일반적인 운전 스택을 구축하기 위해 이러한 모든 문제를 실제로 해결해야 합니다. 이러한 스택은 인간처럼 빠르고 효율적이면서 모든 속도에서 안전해야 합니다.
Large Compute
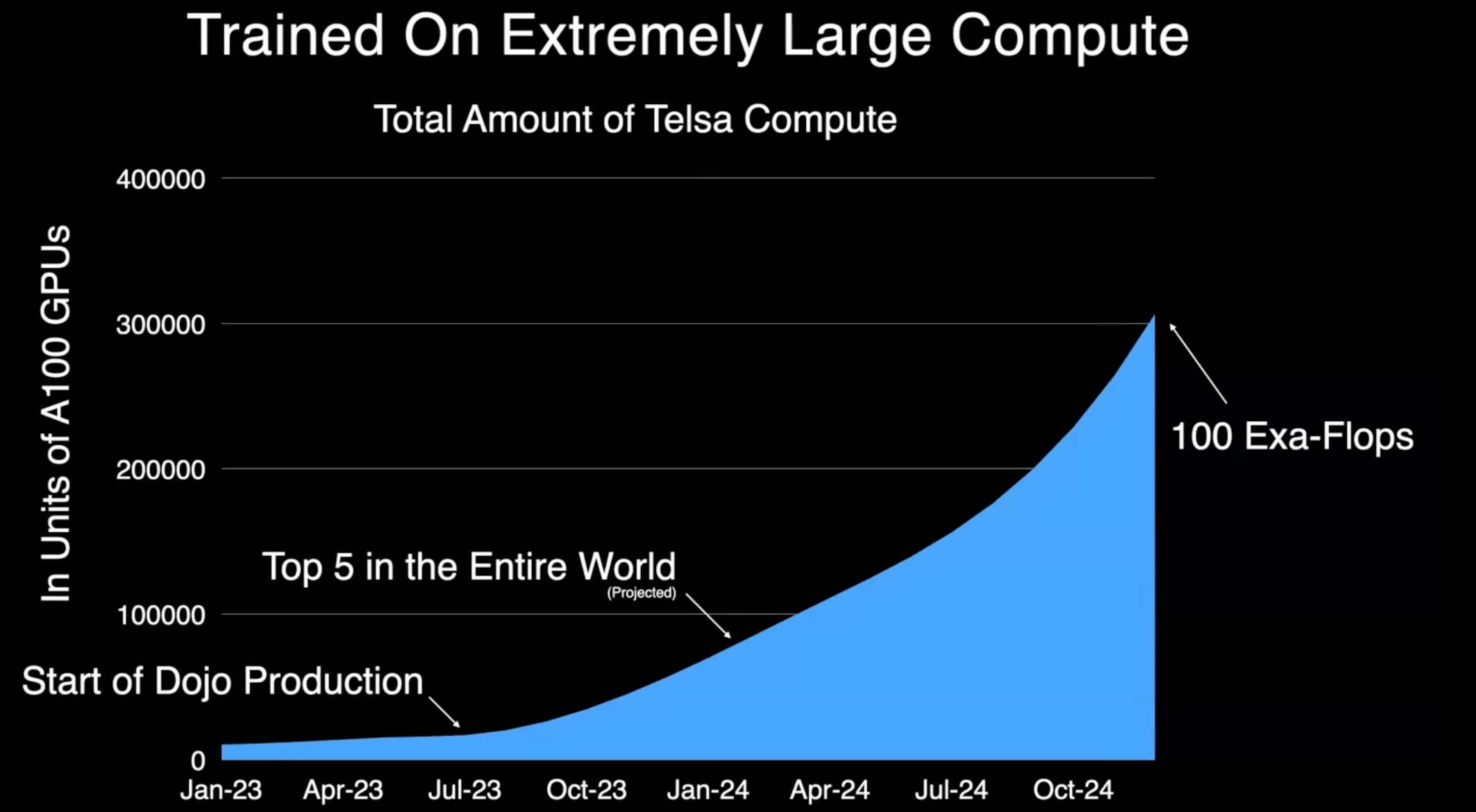
물론 이러한 모든 모델을 훈련하는 데는 상당한 컴퓨팅 리소스가 필요하며, 그래서 Tesla는 컴퓨팅 분야의 세계 리더가 되기를 목표로 하고 있습니다. Dojo는 Tesla에서 직접 제작한 훈련용 하드웨어로, 다음 달에 생산을 시작하게 됩니다. 이를 통해 우리는 전 세계에서 최고의 컴퓨팅 플랫폼 중 하나로 가는 길에 있다고 생각하며, 시각을 위한 이러한 기반 모델을 훈련하기 위해 많은 컴퓨팅 리소스가 필요하다고 생각합니다. 단지 하나의 모델을 위한 컴퓨팅뿐만 아니라 어떤 모델이 실제로 잘 작동하는지 확인하기 위한 다양한 실험을 수행하기 위한 컴퓨팅이 필요하다고 생각합니다.

앞선 내용이 자동차만을 위해 만들어지는 것이 아니라 로봇을 위해서도 만들어지고 있다는 것입니다. 예를 들어, 이미 Occupancy Network를 가지고 있으며, 다른 몇 개의 네트워크도 자동차와 로봇 사이에서 공유되며 실제로 잘 작동하며 이러한 플랫폼을 통해 일반화됩니다. 우리는 차선과 차량과 같은 작업을 다른 플랫폼으로도 확장하려고 합니다. 예를 들어, 로봇이 도로로 걸어가서 주변을 살펴본다면 도로와 차량을 이해하고 차량의 움직임 등을 이해해야 합니다. 이 모든 것은 자동차뿐만 아니라 모든 플랫폼에서도 사용할 수 있도록 구축되어야 합니다. 미래의 로봇 플랫폼에서도 필요한 것입니다.
'Review > Conference & Seminar' 카테고리의 다른 글
| [세미나 리뷰] AI Robotics KR 2024 후기(2024.08.10) (8) | 2024.08.31 |
|---|---|
| [세미나 리뷰] SLAM KR 2023 후기 (2023.11.25) (0) | 2024.08.25 |

