
Priceless
[Paper] PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers 리뷰 본문
[Paper] PIDNet: A Real-time Semantic Segmentation Network Inspired by PID Controllers 리뷰
Hyun__ 2024. 6. 7. 19:07참고
PIDNet 논문을 번역했습니다.
기록용으로 올립니다.
아직 미완성 번역이지만 추후에 다시 읽을 때 수정하겠습니다.
오번역, 오타 지적해주시면 감사하겠습니다.
0. Abstractf
Two-branch Network 구조는 실시간 Semantic Segmentation에서 효율성과 성능을 입증했다. 그러나 고해상도 디테일과 Low-frequency Context를 직접 Fusion하는 것은 Detailed Feature가 주변 정보에 의해 쉽게 사라지는 단점이 있다. 이러한 실패 현상은 Two-branch Model의 Segmentation 정확도를 높이는 것을 제한했다. 이 논문에서는 CNN과 PID controller를 결합했고, Two-branch Network가 필연적으로 비슷한 실패를 겪는 PI Controller와 동등하다는 것을 밝혀냈다. 이 문제를 해결하기 위해 우리는 기발한 Three-branch Network 구조를 제안한다. PIDNet은 Detailed, Context, Boundary 정보를 세부 분석하는 세 개의 Branch가 있고, Detailed branch와 Context branch를 섞기 위한 Boundary Attention을 사용한다. PIDNet의 추론 속도와 정확도 간의 trade-off는 Cityscapes와 CamVid 데이터셋에서 비슷한 추론 속도를 가진 기존의 모델들을 앞지른다.
1. Introduction
PID controller는 현대 동역학 시스템에 쓰이는 기본적인 개념이고 로봇, 화학, 전자 시스템을 처리하는데 사용된다. 많은 발전된 control 전략이 최근 몇 년간 나왔지만, PID controller는 여전히 강건함과 안정성으로 많은 선택을 받고 있다. 나아가 PID controller의 아이디어는 다양한 영역으로 확장되었다. 예를 들어, 연구자들은 PID의 개념을 image denoising, SGD, 수치적 최적화 등에 사용했다. 이 논문에서 PID 제어의 기본 개념을 사용하여 우리는 real-time semantic segmentation을 위한 새로운 구조를 제안하고, 우리 모델의 성능은 이전 모델의 성능을 능가하고 속도와 정확성에서 최고의 trade-off를 달성했다.
Semantic segmentation은 입력 이미지를 픽셀마다 특정 클래스 레이블로 장면을 분석하는 작업이다. 요구 성능 향상으로, semantic segmentation은 다양한 분야의 기본적인 perception 구성요소이다. 기존의 FCN에서 시작하여, DCNN은 점진적으로 많은 모델을 정복했다. 더 나은 성능을 위해 중요한 detail을 잃어버리지 않는 큰 scale의 픽셀 사이에서 contextual dependencies의 학습의 가능성과 함께 모델을 사용하기 위해 소개되었다. 이 모델들은 높은 정확도의 segmentation을 수행했지만 많은 자원이 소요되고, 이는 자율주행과 로봇같은 real-time scenario에서 사용을 방해한다.
real-time과 mobile의 요구사항을 만족하기 위해 연구자들은 효과적이고 효율적인 모델을 고안해냈다. 특히 ENet은 lightweight decoder를 적용했고, early stages에서 feature map을 downsample했다. ICNet은 높은 수준의 semantic을 수행하기 위해 복잡하고 긴 경로에 작은 크기의 입력을 encoding했다. MobileNet은 기존의 convolution을 depth-wise separable convolution으로 대체했다. 이 연구들은 segmentation 모델의 메모리 사용량과 지연을 낮췄지만 낮은 정확성은 실사용에 한계가 있었다. 최근에 참신하고 유망한 최근의 모델은 Two-branch Network(TBN)기반의 구조가 제안되었고 속도와 정확도의 trade-off의 SOTA를 달성했다.
이 논문에서 PID 제어의 관점으로부터 TBN 구조를 봤고, TBN은 overshoot으로부터 성능이 저하되는 PI 제어와 동등한 것을 지적한다. 이 문제를 해소하기 위해 PIDNet이라는 Three-branch network 구조를 제안한다. 그리고 Cityscapes,CamVid, PASCAL Contest 데이터셋에서 우월성을 증명한다. 또한 PIDNet의 각 모듈의 기능을 이해하기 위해 feature 시각화를 보여준다. github 참고.
이 논문의 주 기여는 다음과 같다.
- 우리는 DCNN과 PID 제어를 결합했고, PID 제어 구조 기반 three-branch network 구조들을 제안한다.
- Bag fusion module과 같이 detailed와 context feature의 균형을 위해 설계된 효율적인 모듈은 PIDNets의 성능을 강화하기 위해 제안되었다.
- PIDNet은 속도와 정확성에서 최고의 trade-off를 달성했다. 특히 PIDNet-s는 빠르고 PIDNet-L은 높은 정확성을 실시간으로 구현한다.
2. Related Works
높은 정확도와 실시간성을 지향하는 Representative methods는 이 section에서 별도로 논의된다.
2.1. High-accuracy Semantic Segmentation
semantic segmentation에 대한 선행 연구는 encoder-decoder 구조 기반이며 encoder는 stride와 pooling을 통해 receptive field가 점차적으로 커졌으며, decoder는 deconvolution이나 upsampling을 사용하여 high-level semantics으로부터 세부 정보를 얻었다. 그러나 spatial details은 encoder-decoder 구조의 downsampling 과정에서 쉽게 무시될 수 있다. 이 문제를 해결하기 위해 spatial resolution의 감소 없이 시각을 넓힐 수 있는 dilated convolution이 제안되었다. 이를 바탕으로 DeepLab 시리즈는 ….
2.2. Real-time Semantic Segmentation
3. Method
PID 제어는 3가지 요소를 가지고 있다. P(proportional), I(integral), D(derivative) 제어기를 가지고 있다. 각 성분의 요소는 아래와 같다.

PI controller의 구성식은 아래와 같다.
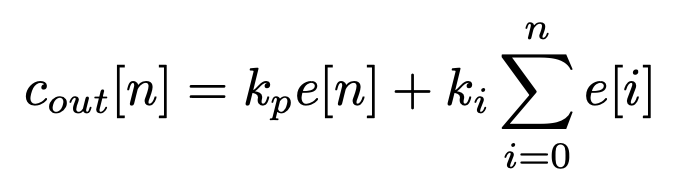
P controller는 현재 시그널에 초점이 맞춰져 있고, I controller는 이전 모든 신호를 축적한다. 축적의 관성력으로 인해 신호가 반대로 변하면 단순한 PI controller의 결과는 overshoot이 발생한다. 그리고 신호가 더 작아질 때 D controller는 negative가 되고 damper로서 overshoot을 방지한다. 유사하게, TBN은 multiple convolutional layer로부터 context와 세부 정보를 분석한다.
PID Control의 1차원에 대한 예시…
정리된 PID control의 식은 아래와 같다.
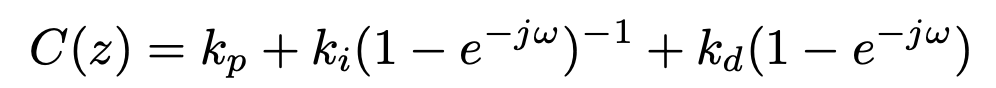
3.1. PIDNet: A Novel Three-branch Network
overshoot 문제를 개선하기 위해, 우리는 auxiliary derivative branch(ADB)를 TBN에 추가하여 PID controller를 공간적으로 속이고 고주파 성분의 분할 정보를 강조한다. 각 객체의 내부 픽셀을 위한 분할은 일정하고 객체에 인접한 경계들 사이에서는 일정하지 않다. 그래서 difference of semantics는 오직 객체의 경계와 ADB의 목표가 가장자리 검출일 때 0이다. 따라서 우리는 새로운 three-branch real-time semantic segmentation 구조인 PIDNet을 달성했다.
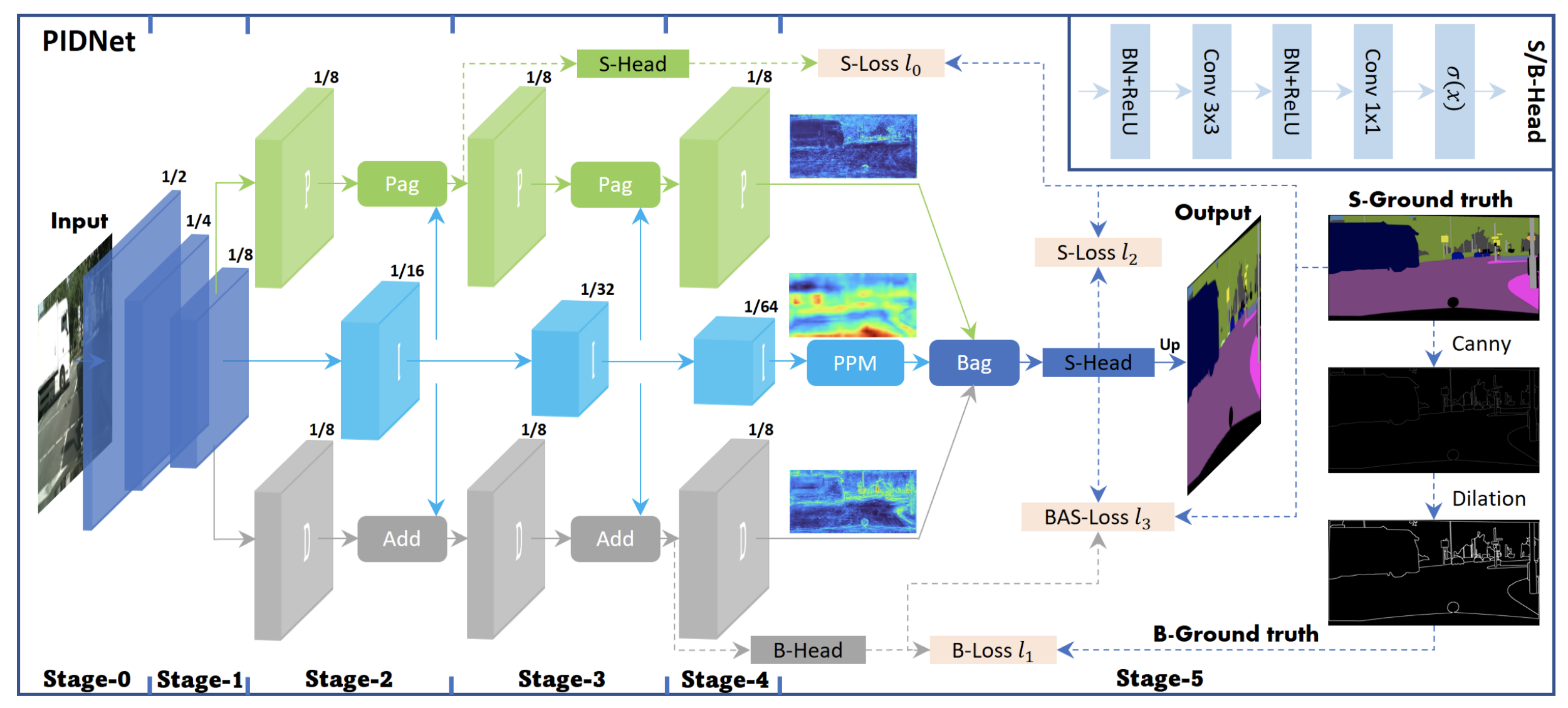
PIDNet은 보충 기능을 가진 3개의 branch를 가지고 있다. P branch는 고해상도 feature map에서 세부 정보를 분석하고 보존한다. I branch는 큰 범위의 종속성을 분석하기 위해 context 정보를 locally and globally하게 통합한다. D branch는 고주파 특징을 추출하여 경계 영역을 예측한다. 그리고 우리는 하드웨어와 호환성을 위해 backbone으로 cascaded residual blocks를 사용한다. 반면에 P,I,D branch의 깊이는 효율적인 실행을 위해 3단계로 구성되어 있다. 결과적으로 PIDNet family(PIDNet-S,M,L)는 모델을 깊고 넓게 쓰면서 생성되었다.
우리는 semantic heads를 first Pag module의 결과에 두어 추가적인 semantic loss(L0)를 만들어 더 나은 최적화 성능을 이끌어냈다. dice loss 대신 weighted binary cross entropy loss(L1)을 적용하여 거친 경계는 경계 영역을 강조하는 것을 선호하고 작은 객체들의 특징을 강조하기 때문에 경계 검출의 불균형 문제를 해결했다. L2와 L3는 CE Loss를 나타내고, 우리는 semantic segmentation과 경계 검출을 구성하고 Bag 모듈을 구성하기 위해 boundary head의 결과를 사용하는 L3를 boundary-awareness CE Loss를 사용한다. BAS-Loss 계산식은 아래와 같다.
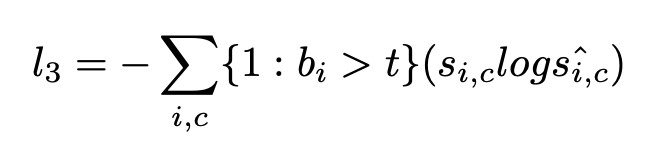
t가 사전 정의된 threshold와 b를 참고할 때 각각의 s, s hat는 boundary head, segmentation ground-truth와 i 번째 픽셀의 prediction 클래스 결과인 c이다. 고로 PIDNet의 최종 Loss는 아래와 같다
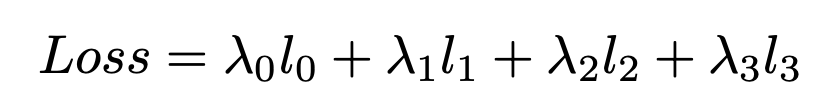
경험을 토대로 우리는 파라미터를 아래와 같이 설정했다.
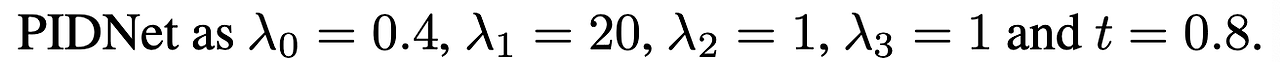
3.2. Pag: Learning High-level Semantics Selectively
구현 과정에서 사용된 lateral connection은 다른 scale의 feature map사이의 정보 전달을 강화했고, 모델의 표현성을 개선했다. PIDNet에서 I branch로부터 제공된 충분하고 정확한 semantic 정보는 detail을 분석하고 P와 D branch의 경계 검출에서 중요하다. 고로 우리는 I branch를 다른 두 branch의 backup으로 간주하고 필요한 정보를 제공하게 했다. 제공된 feature map을 바로 더하는 D branch와 달리, 우리는 Pixel-Attention-Guided fusion module(Pag) 을 소개하고 구조는 아래와 같다.
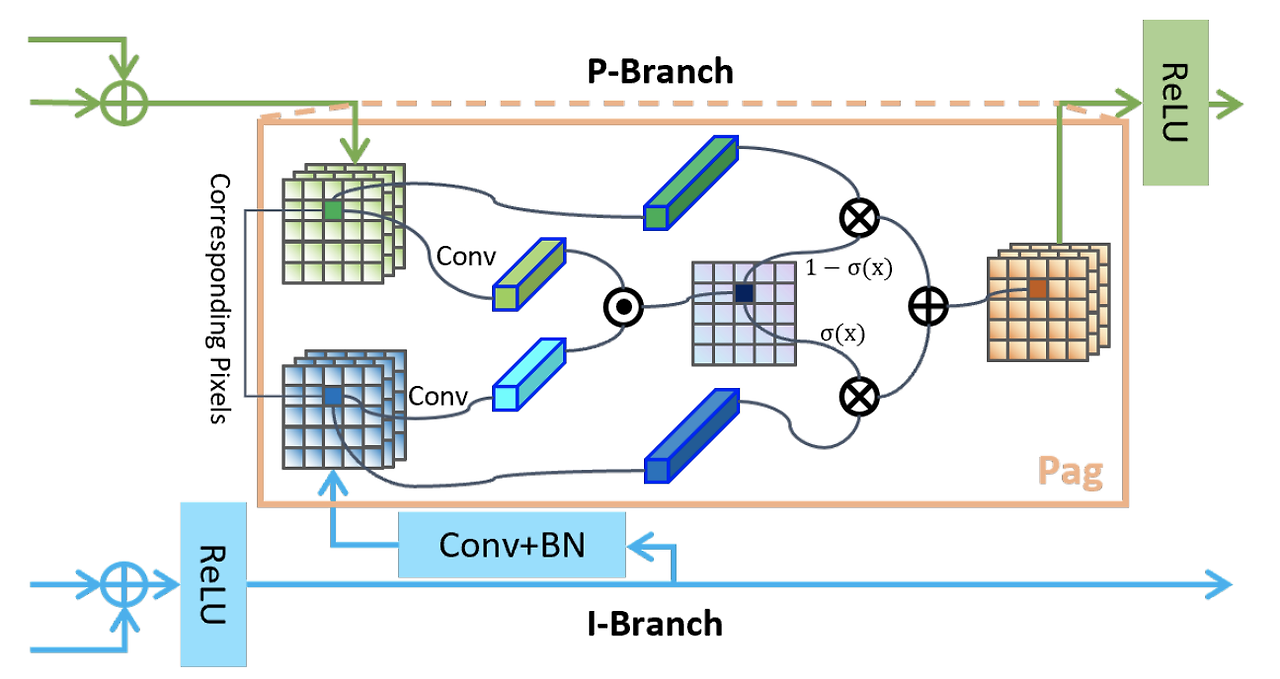
P branch는 I branch로부터 얻은 유용한 semantic feature를 압도되지 않고 선택적으로 학습한다. Pag의 배경 개념은 attention mechanisms으로부터 가져왔다. P와 I branch으로부터의 feature map에 대응하는 픽셀의 벡터를 vp와 vi라 정의하고, sigmoid 함수의 결과는 아래와 같이 표현할 수 있다.
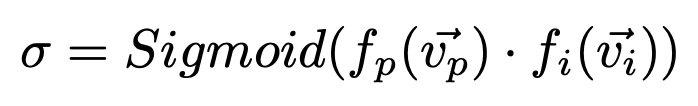
sigma는 두 픽셀이 같은 객체에 속한 확률을 의미한다. sigma가 높을 때 우리는 vi를 더 신뢰한다. I branch는 의미론적으로 신뢰도가 높고 정확하기 때문이고 반대 경우도 마찬가지다. 고로 Pag의 결과는 아래와 같이 쓸 수 있다.
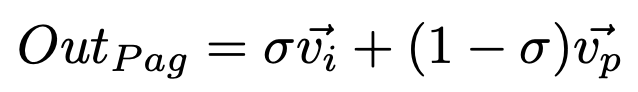
3.3. PAPPM: Fast Aggregation of Contexts
나은 global scene prior 구조를 위해 PSPNet은 pyramid pooling module(PPM)을 소개했고, 이는 local and global context representation 을 만들기 위한 convolution layer 이전에 multi-scale pooling maps을 연결했다. Deep Aggregation PPM(DAPPM)은 PPM의 훨씬 향상된 context embedding 가능성을 제안했고 좋은 성능을 보였다. 그럼에도 불구하고 DAPPM의 계산 프로세스는 깊이를 고려하여 병렬화 되지 않았고, 이는 시간을 많이 소비하고 DAPPM은 각 스케일마다 너무 많은 채널을 가지고 있다. 이는 가벼운 모델의 표현 가능성을 초과할 수 있다. 그래서 우리는 DAPPM의 연결을 수정하여 병렬화 할 수 있게 했고, 이는 아래 그램과 나타난다.
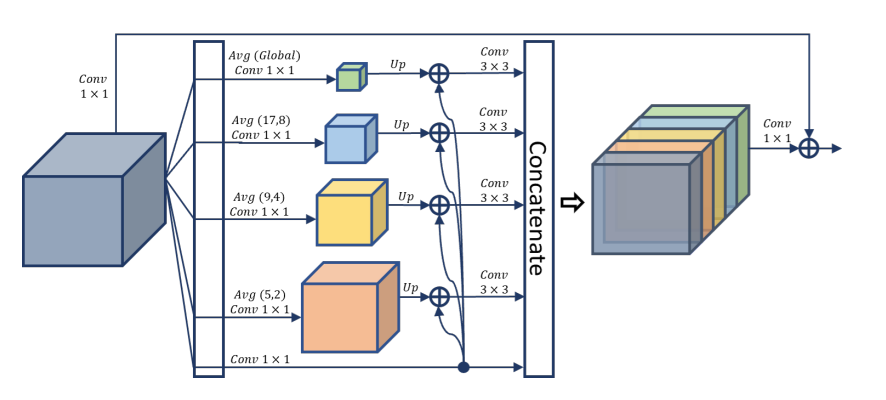
이를 통해 128 채널에서 96 채널까지 scale을 줄였다. 이 새로운 context 얻는 모듈은 Parallel Aggregation PPM(PAPPM)이라 불리고 PIDNet-M과 PIDNet-S에 적용하여 속도를 확보했다. 깊은 모델인 PIDNet-L은 DAPPM을 사용하여 깊이를 고려한다. 하지만 계산 속도가 느려지고 채널 수가 감소한다
3.4. Bag: Balancing the Details and Contexts
ABD에 의해 추출된 경계 feature가 주어졌을 때, 우리는 fusion of detailed(P)와 context(I) representation을 안내하기 위해 boundary attention을 사용한다. 구체적으로 우리는 Boundary-Attention Guided fusion module(Bag)을 설계했고 구조는 아래와 같다.
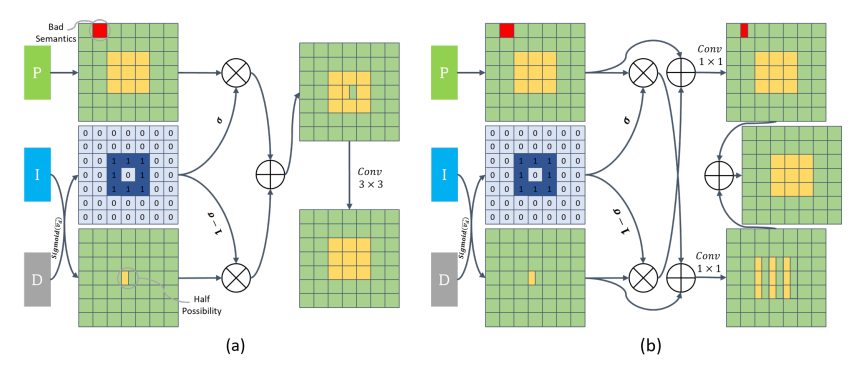
고주파 영역을 채우고 저주파 영역을 context feature로 채운다. context branch는 의미론적으로 정확하지만 너무 많은 공간적, 기하학적 정보를 잃을 수 있다는 것을 명심해야 한다. 특히 경계 영역과 작은 물체에서. 공간적 detailed를 보존하는 detailed branch 덕분에 우리는 모델이 detailed branch를 경계 영역 따라 신뢰할 수 있도록 하고 context feature를 다른 영역에 채우도록 사용한다. P,I,D feature map에 대응하는 픽셀의 벡터를 vp, vi vd라 했을 때, sigmoid 의 결과, Bag, light-bag의 결과는 아래와 같다.
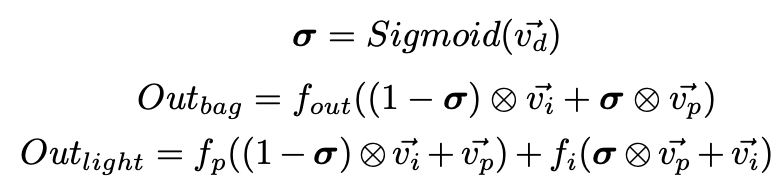
f가 convolution의 구성 요소를 참고할 때, 배치 정규화와 ReLU를 수행한다. 3x3 conv를 Bag에서, 2개의 1x1 conv로 Light-Bag에서 대체하지만, Bag과 Light-Bag의 기능적 부분은 유사하다. 이는 sigma가 0.5보다 클 때 모델은 detailed feature를 더욱 신뢰하고 반대의 경우 context information을 선호한다.

