
Priceless
[컴퓨터] Computer Systems: A Programmer's Perspective 챕터2 정리 본문
Computer Systems: A Programmer's Perspective
위 책의 내용을 정리하였습니다
Chapter 2: Representing and Manipulating Information (정보 표현과 처리)
대부분의 컴퓨터는 메모리의 개별 비트에 access하는 대신, 8비트의 블록, 즉 바이트를 주소가 지정 가능한 최소 단위를 메모리를 사용한다
저장하고 있는 값이 너무 크면 오버플로우가 발생할 수 있다
비트 레벨의 값에 대해 운영 체제와 컴파일러 마다 다르게 연산되면
보안에 취약한 문제가 발생할 수 있다
2-1. Information Storage (정보 저장)
C의 포인터 값은 다양한 타입의 변수의 저장 블록의 첫 번째 바이트 주소이다
프로그램 데이터, 명령 및 제어 정보를 저장하기 위해
객체의 주소는 어떻게 될 것이며, 메모리에서 바이트를 어떻게 배열할 것인지 다룬다
2-1-1. Hexadecimal Notation (16진수 표기법)
1byte = 8bits
2진수(binary): 00000000(2) 부터 11111111(2)
0과 1로 나타낸다
10진수(decimal): 0(10) 부터 256(10)
0부터 9까지 나타낸다
16진수(hexadecimal):0(16)부터 FF(16)
0부터 9, A부터 F까지 나타낸다

2-1-2. Word(워드)
모든 컴퓨터는 정수와 포인터 데이터의 size를 나타내는 word 크기를 가지고 있다
컴퓨터가 데이터를 처리하는 기본 단위를 word라 한다
우리가 알고 있는 PC 사양에서 32bit와 64bit가 이 word 크기에 해당한다
Word Compatibility
CPU와 OS(혹은 어플리케이션)가 지원하는 word size가 다를 수 있다
32bit의 CPU에서 32bit의 OS가 작동하지만
32bit의 CPU에서 64bit의 OS가 작동하지 않는다
반대의 경우로
64bit의 CPU에서 64bit의 OS가 작동하며
64bit의 CPU에서 32bit의 OS는 작동한다(하위호환)
가상 주소는 word에 의해 인코딩 되므로 word 크기에 의해 가상 주소 공간의 최대 크기가 결정된다
그래서 32bit 시스템인 경우 최대 할당 가능한 메모리가 2^32 byte인 4GB가 최대인 반면,
64bit인 경우 최대 할당 가능한 메모리가 2^64 byte로 훨씬 더 크게 사용할 수 있다
word size(32bit와 64bit)에 관한 설명
64비트 32비트 CPU와 운영체제 에 대하여 :: 아인스트라세의 SW 블로그 (tistory.com)
2-1-3. Data Size(데이터 타입 크기)
컴퓨터의 아키텍쳐와 컴파일러에 따라
데이터 타입이 정의된 크기가 다를 수 있다

이러한 종속성을 이해하고 프로그램을 개발해야 한다
그렇지 않다면 프로그램을 새로운 컴퓨터에서 사용할 때 각종 버그가 발생할 수 있다
[교수님 피드백]
환경에 따라 달라지는 data size 문제를 해결하기 위해
low level 작업에서는 크기가 확실히 정해진 data type인
int8_t, int 32_t 와 같은 type을 사용한다
2-1-4. Addressing and Byte Ordering(주소 정하기와 바이트 정렬)
multi-byte객체의 byte는 연속된 순서로 저장되며, 객체의 주소는 사용된 바이트 중 가장 작은 주소로 주어진다
예를 들어, int 타입의 변수 x가 주소 0x100에 있는 경우,
즉 주소 표현식 &x의 값이 0x100인 경우,
x의 4바이트는 메모리 위치 0x100, 0x101, 0x102 및 0x103에 저장된다
- 객체를 나타내는 byte를 정렬하는 방법
little endian: 최하위 바이트가 먼저 오는 방식, 대부분의 Intel 시스템에 사용
big endian: 최상위 바이트가 먼저 오는 방식, IBM 등 다른 시스템에 사용
bi-endian: 둘 다 사용 가능한 규약, 최근에 많이 사용
데이터 전송 과정에서 byte 정렬이 일치해야 문제가 발생하지 않는다
[교수님 피드백]
실제로 아키텍처 간 취하는 endian이 달라
발생하는 버그가 많으니 다른 아키텍처 간의 cross compile 과정에서는 무조건 확인해야 한다
int 타입의 변수 x가 주소 0x100에 있고 16진수 값이 0x01234567인 경우
endian에 따른 주소 범위 0x100에서 0x103까지의 바이트 순서
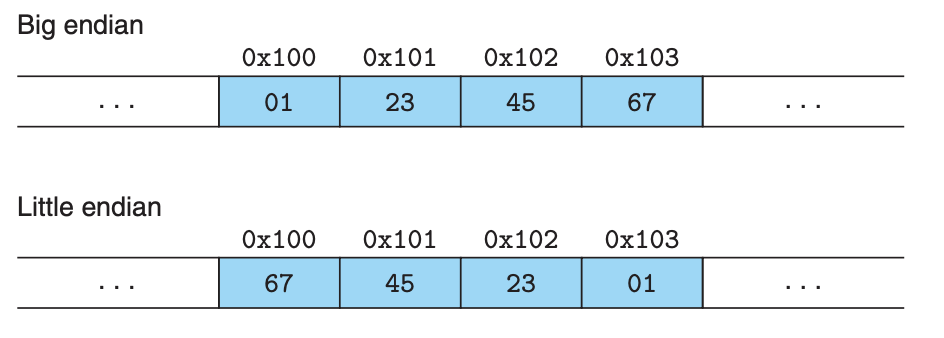
바이트 순서를 알 수 있는 경우 type을 바꿀 수 있는 프로그램을 작성할 수 있다
C 언어에서는 다른 형식의 객체를 참조할 수 있도록 cast를 사용할 수 있다

"unsigned char"의 객체에 대한 포인터로 byte_pointer 데이터 형식을 정의하기 위해 typedef를 사용한다
show_bytes 함수는 바이트 포인터로 표시된 바이트 시퀀스의 주소와 바이트 개수를 입력으로 받는다
그것은 각각의 바이트를 16진수로 출력한다
show_int, show_float 및 show_pointer 함수는
각각 int, float 및 void * 타입의 C 프로그램 객체의 바이트 표현을 출력하는 방법을 보여주는 함수다
2-1-5. Representing Strings(문자열 표현)
string은 null(0)로 종료된 문자의 배열에 의해 인코딩된다
보통 ASCII 문자를 나타내며, unicode standard를 통해 한국어를 포함한 다른 언어를 지원한다
UTF-8 representation은 각 문자를 연속적인 바이트로 인코딩하며,
표준 ASCII 문자는 ASCII에서와 동일한 단일 바이트 인코딩을 사용하므로
모든 ASCII 연속적인 바이트는 UTF-8에서 ASCII와 동일한 의미를 가진다
unicode와 utf-8에 관한 설명
Unicode와 UTF-8 간단히 이해하기. 유니코드(Unicode) | by Jeong Dowon | Medium
2-1-6. Representing Code(코드 나타내기)


같은 코드라 하더라도 프로세서와 OS 등에 따라 다르게 인코딩 될 수 있다
2-1-7. Boolean Algebra

2진수 기준
~[¬](NOT): 반대를 리턴, 0 -> 1, 1 -> 0
&[∧](AND): 둘 다 1이면 1
| [∨](OR): 둘 중 하나라도 1이면 1
^[⊕](Exclusive-Or, XOR): 둘 중 하나만 1이면 1
bit 벡터는 집합을 표현하는 것에도 사용할 수 있다
a = [01101001]는 집합 A = {0, 3, 5, 6}을 인코딩
b = [01010101]은 집합 B = {0, 2, 4, 6}을 인코딩한다고 할 때
연산 a & b는 비트 벡터 [01000001]을 생성하고,
A ∩ B = {0, 6} 가 나타난다
2-1-8. Bit-Level Operation in C(C언어의 비트 레벨 연산)
bit-level 연산의 대표적인 예시는 masking 연산이다
bit masking은 이진수 표현을 자료구조로 사용하여 연산하는 방법을 말한다
비트마스킹에 대한 설명
[알고리즘] 비트마스킹(bitmasking) 이란 :: 굳건하게 (tistory.com)
2-1-9. Logical Operations in C(C언어의 논리 연산)

논리 연산자 ||, && 및 ! 는 Or, And 및 Not 연산과 대응되며,
bit-level 연산자와는 다른 기능이다
논리 연산자는 0이 아닌 모든 인수를 True로 취급하고 0을 False로 취급한다
연산 결과로는 true(1) 혹은 false(0)를 리턴한다
논리 연산자는 첫 번째 성분에서 평가가 완료되는 경우 두 번째 성분을 평가하지 않는다
예를 들어 'a && 5/a' 식에서 a가 0이면 false이므로 0으로 나누기가 발생하지 않는다
2-1-10. Shift Operation in C(C언어의 쉬프트 연산자)

shift 연산은 연속된 비트를 왼쪽이나 오른쪽으로 이동시키는 연산을 말한다
x << k의 경우
x를 나타내는 제일 앞에 있는 k 개의 비트를 버리고 제일 뒤에 k 개의 0을 채운다
00111 << 1 = 01110
x >> k의 경우
logical shift: x를 나타내는 제일 뒤에 있는 k 개의 비트를 버리고 제일 앞에 k 개의 0을 채운다. unsigned 한정자에서 사용
11100 >> 1 = 01110
arithmetic shift: x를 나타내는 제일 뒤에 있는 k 개의 비트를 제일 앞으로 옮긴다. 대부분 이 방법을 사용
00111 >> 1 = 10011
2-2. Integer Representation(정수 표현)
2-2-1. Integral Data Types(정수 데이터 타입)
대부분의 64bit 시스템은 8byte 표현을 사용하며, 32bit 시스템에서 사용되는 4byte 표현보다 훨씬 넓은 범위의 값을 제공한다
음수의 범위가 양수의 범위보다 하나 더 크다
이는 음수를 나타내는 비트가 사용되지 않기 때문이다


c언어는 데이터 타입이 나타낼 수 있는 최소(보장된) 범위를 지정하며
int 타입의 경우 아래와 같다
최소 범위는 음수의 범위와 양수의 범위가 같다


2-2-2. Unsigned Encodings
w-bit의 정수를 가진 비트 벡터 x를 나타내는 B2U 함수(binary to unsigned)


각 수에 해당하는 bit는 유일하다(전사 함수)
4bit인 경우 0부터 15를 나타낼 수 있다
2-2-3. Two's-Complement Encodings(2의 보수 인코딩)
w-bit의 벡터에서 부호 비트를 포함한 정수를 나타내는 B2T 함수(Binary to Two's complement)
부호 비트가 1이면 음수이고, 0이면 음수가 아니다
부호 비트는 벡터 중 제일 앞의 수이다


4bit인 경우 -8부터 7을 나타낼 수 있다
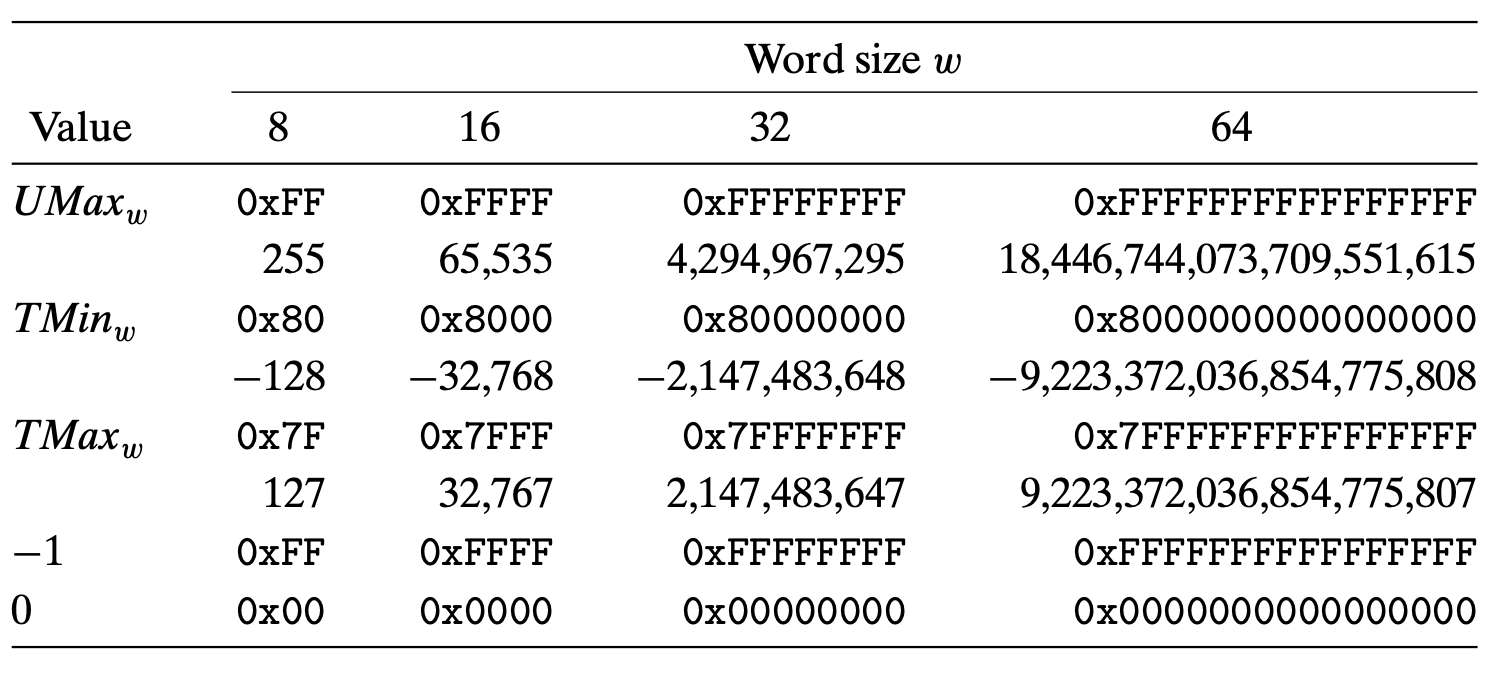
Unsigned 일때와 Two's complement일 때와 나타내는 최대값과 최소값의 범위가 다르다
또한 -1을 나타내는 비트와 최대값을 나타내는 비트 표현 방식이 같다
2-2-4. Conversions Between Signed and Unsigned(signed와 unsigned 사이의 전환)
C언어에서 다른 타입의 숫자 간에 캐스팅을 할 때 값을 보존해야 한다


두 타입의 범위는 아래와 같으므로
겹치는 범위에 대해서는 같은 수에 대해 동일한 비트가 나타날 것이다



2의 보수를 unsigned type으로 캐스팅하는 함수는 다음과 같다


bit 크기를 2의 제곱한 만큼 큰 값이 나타난다
unsigned type을 2의 보수로 캐스팅하는 함수는 다음과 같다


범위보다 더 큰 값은 음수로 나타난다
2-2-5. Signed vs Unsigned in C
2-2-6. Expanding the Bit Representation of a Number(숫자의 비트 표현 확장하기)
2-2-7. Truncating Numbers(숫자 자르기)
2-2-8. Advice on Signed vs Unsigned
[교수님 피드백]
정수 타입도 중요하지만 floating 타입을 이해하면 더욱 좋을 것이다
'CS' 카테고리의 다른 글
| [컴퓨터] Computer Systems: A Programmer's Perspective 챕터3 정리 (0) | 2023.11.07 |
|---|---|
| [컴퓨터] Computer Systems: A Programmer's Perspective 챕터4 정리 (0) | 2023.10.26 |
| [컴퓨터] Computer Systems: A Programmer's Perspective 챕터1 정리 (0) | 2023.09.14 |
